
این متن دومین مطلب آزمایشی من است که به زودی آن را حذف خواهم کرد.
زکات علم، نشر آن است. هر
وبلاگ می تواند پایگاهی برای نشر علم و دانش باشد. بهره برداری علمی از وبلاگ ها نقش بسزایی در تولید محتوای مفید فارسی در اینترنت خواهد داشت. انتشار جزوات و متون درسی، یافته های تحقیقی و مقالات علمی از جمله کاربردهای علمی قابل تصور برای ,بلاگ ها است.
همچنین
وبلاگ نویسی یکی از موثرترین شیوه های نوین اطلاع رسانی است و در جهان کم نیستند وبلاگ هایی که با رسانه های رسمی خبری رقابت می کنند. در بعد کسب و کار نیز، روز به روز بر تعداد شرکت هایی که اطلاع رسانی محصولات، خدمات و رویدادهای خود را از طریق
بلاگ انجام می دهند افزوده می شود.
این متن اولین مطلب آزمایشی من است که به زودی آن را حذف خواهم کرد.
مرد خردمند هنر پیشه را، عمر دو بایست در این روزگار، تا به یکی تجربه اندوختن، با دگری تجربه بردن به کار!
اگر همه ما تجربیات مفید خود را در اختیار دیگران قرار دهیم همه خواهند توانست با انتخاب ها و تصمیم های درست تر، استفاده بهتری از وقت و عمر خود داشته باشند.
همچنین گاهی هدف از نوشتن ترویج نظرات و دیدگاه های شخصی نویسنده یا ابراز احساسات و عواطف اوست. برخی هم انتشار نظرات خود را فرصتی برای نقد و ارزیابی آن می دانند. البته بدیهی است کسانی که دیدگاه های خود را در قالب هنر بیان می کنند، تاثیر بیشتری بر محیط پیرامون خود می گذارند.
اولین گام در انجام تجزیه و تحلیلهای آماری شناخت انواع گوناگون متغیرها می باشد. اهمیت این شناخت از آنجا ناشی می شود که آزمونهای آماری مناسب برای انواع مختلف داده ها فرق می کنند. در این نوشته قصد داریم مختصری در مورد انواع مختلف متغیرها بحث کنیم.
انواع متغیرها از لحاظ مقادیر عددی (پیوستگی و گسستگی)
در علم آمار فارغ از اینکه متغیرها مستقل یا وابسته باشند به دو گروه تقسیم می شوند :
متغیرهای پیوسته متغیرهایی هستند که می توانند بی نهایت عضو داشته باشند. برای نمونه سن افراد، فشار خون، قد، وزن و . همه متغیر های پیوسته هستند . مقدار این گونه متغیرها در هر عضو نمونه در صورتی که ابزار اندازه گیری دقیق باشد می توانند تا بی نهایت ادامه پیدا کنند.
متغیرهای گسسته برخلاف متغیرهای پیوسته تعداد سطوح محدودی دارند. برای مثال متغیر جنسیت دارای دو سطح زن و مرد است و هر شخص در جامعه مورد بررسی یا زن خواهد بود یا مرد و یا متغیر سطح تحصیلات دارای سطوح محدود، زیردیپلم، دیپلم و بالاتر از دیپلم است و مانند متغیر پیوسته بی نهایت سطح ندارد . متغیرهای نظیر جنسیت، سطح تحصیلات، تعداد فرزند، وضعیت تأهل، استان محل زندگی و . از این دسته هستند.
✍️ متغیرهای گسسته خود به دو دسته متغیرهای اسمی گسسته و ترتیبی گسسته تقسیم می شوند .
متغیرهایی مانند سطح تحصیلات و تعداد فرزند که بین سطوح آنها یک رابطه منطقی برقرار است متغیر گسسته ترتیبی هستند برای نمونه کسی که سطح تحصیلات دیپلم دارد حتماً دارای سطح تحصیلات بالاتر از کسی است که سطح تحصیلات زیر دیپلم داشته است و یا کسی که ۴ فرزند دارد از کسی که ۳ فرزند دارد تعداد فرزند بیشتری دارد . به این متغیرهای گسسته که بین سطوح آنها یک ترتیب منطقی برقرار است متغیر گسسته ترتیبی گویند.
به متغیرهای گسسته ای که بین سطوح آنها رابطه منطقی (بزرگتر، کوچکتر، مساوی ) در صفت مورد بررسی برقرار نیست مانند جنسیت، تأهل و محل زندگی متغیر گسسته اسمی گویند.
انواع متغیرها از لحاظ مقیاس اندازه گیری
متغیر ها از نظر مقیاس سنجش و اندازه گیری به چهار دسته تقسیم می شوند:
۱) اسمی
۲) رتبه ای یا ترتیبی
۳) فاصله ای
۴) نسبی یا نسبتی
مقیاس های اسمی و رتبه ای مخصوص داده های کیفی هستند و مقیاس های فاصله ای و نسبی مخصوص داده های کمی می باشند. به بیان دیگر اعداد حاصل از مقیاسهای اندازه گیری اسمی و رتبه ای از نوع گسسته و اعداد حاصل از مقیاسهای فاصله ای و نسبتی از نوع پیوسته هستند.
↩️مقیاس اسمی
در مقیاس اسمی داده ها بر اساس یک صفت یا ویژگی گروهبندی می شوند.در این طبقه بندی هیچ ترتیب خاصی بر طبقه ها حاکم نیست و آنها جدای از هم قرار دارند. به هر یک از طبقه ها می توان عددی را اختصاص داد، اما این عدد ارزش کمی یا مقداری نداشته و تابع قوانین ریاضی نیست. برای نمونه می توان در زمان ورود داده ها به رایانه، برای سهولت کار به زن کد شماره ۱ و به مرد کد شماره ۲ را اختصاص داد اما این بدان معنی نیست که ارزش مرد دو برابر ارزش زن است.
↩️مقیاس رتبه ای
مقیاس رتبه ای یا ترتیبی نسبت به مقیاس های اسمی پیشرفته تر هستند و در آنها می توان شدت و ضعف یک صفت یا ویژگی را نیز بررسی کرد.این نوع مقیاس ها در خصوص داده هایی هستند که بر اساس یک نظام سلسله مرتبه ای ترتیب بندی یا رتبه بندی می شوند. هر چند رتبه ها را می توان با روشهای گوناگون آماری با هم مقایسه کرد، اما آنها ارزش عددی ندارند و ارزش آنها در ارتباط یا تناسب با رتبه های دیگر مشخص می شود. در این نوع مقیاس رتبه بندی از عدد کم به بالا انجام می گیرد. بعنوان مثال اگر دانشجویی بالاترین نمره را کسب کند شاگرد اول محسوب خواهد شد به عبارت دیگر بالاترین رتبه همیشه یک خواهد بود و تفاوت بین یک رتبه با رتبه بعدی نیز بدون توجه به مقدار صفت یا ویژگی مورد نظر همیشه یک خواهد بود مثلاً اگر نفر اول نمره ۲۰ بگیرد شاگرد اول محسوب شده و اگر نفر دوم ۹۹/۱۹ بگیرد شاگرد دوم و اگر نفر سوم ۱۴ بگیرد شاگرد سوم محسوب خواهد شد.
↩️مقیاس های فاصله ای
مقیاس های فاصله ای نسبت به مقیاس های رتبه ای پیشرفته تر هستند و در آنها می توان علاوه بر دارا بودن یک ویژگی یا صفت، کمی یا زیادی آنها را نیز مشخص کرد. برای نمونه، می توان گفت که دانشجویی که نمره ۲۰ گرفته با دانشجویی که نمره ۱۷ گرفته به اندازه ۳ نمره فاصله یا اختلاف دارد. پس مقیاس های فاصله ای در خصوص داده هایی هستند که ارزش عددی دارند و بین دو عدد متوالی با محدودیت معینی عدد دیگری قرار می گیرد و می توان عملیات ریاضی یا آماری را روی آنها انجام داد. در این مقیاس صفر حقیقی یا مطلق نیست بلکه قراردادی است. مثلاً اگر فردی در یک امتحان نمره صفر بگیرد دلیل بر آن نیست که او هیچ چیز ازآن درس نمی داند یا اگر نمره ۲۰ بگیرد دلیل بر آن نیست که همه چیز را در آن حوزه می داند بلکه بر اساس قرارداد یا توافق و ملاکی که توسط استاد تعیین شده است، نمره صفر یا ۲۰ گرفته است. مقیاس هایی نظیر دما، آزمون استعداد، آزمون هوش، نمره های دانشجویان و نظایر اینها از نوع فاصله ای هستند.
↩️مقیاس نسبی
عالی ترین و دقیق ترین سطح سنجش است که در آن علاوه بر تعیین سطوح و مقادیر یک متغیر و فاصله بین مقادیر آن، نسبت ها نیز بر اساس صفر حقیقی یا مطلق تعیین می گردند. هر چیزی که با مقیاس های دقیق فیزیکی نظیر وزن، قد، نیرو، میزان پول و درآمد و غیره انجام می گیرند نیز از این نوعند.
برای داده های این مقیاس، علاوه بر کلیه آماره های ذکر شده در مورد مقیاس فاصله ای، می توان از شاخص هایی نظیر میانگین هندسی و ضریب پراکنش که به صفر حقیقی نیاز دارند، استفاده کرد.
انواع متغیرها از لحاظ نقش آنها در مدل
انواع متغیرها براساس نقش آنها در تحقیق عبارتند از:
متغیر مستقل : متغیر مستقل متغیری است که در پژوهشهای تجربی به وسیله پژوهشگر دستکاری میشود تا تاثیر( یا رابطه) آن بر روی پدیده دیگری بررسی شود.
متغیر وابسته : متغیر وابسته، متغیری است که تأثیر (یا رابطه) متغیر مستقل بر آن مورد بررسی قرار میگیرد. به عبارت دیگر پژوهشگر با دستکاری متغیر مستقل درصدد آن است که تغییرات حاصل را بر متغیر وابسته مطالعه نماید.
متغیر میانجی : این متغیر به عنوان رابط بین متغیر مستقل و متغیر وابسته قرار میگیرد. متغیر میانجی میتواند بر جهت یا شدت رابطه متغیر مستقل و وابسته اثر بگذارد. با توجه به قابل سنجش بودن این متغیر یا هدف پژوهشگر این متغیر می تواند سه نقش زیر را داشته باشد.
متغیر تعدیل کننده : اگر متغیر میانجی قابل سنجش و اندازه گیری باشد و پژوهشگر نیز بخواهد اندازه آن را بسنجد و در مدل وارد کند به آن متغیر تعدیل کننده گویند. متغیر تعدیل کننده متغیری است که بر جهت رابطه یا میزان رابطه متغیرهای مستقل و وابسته می تواند موثر باشد. اثرات این متغیر قابل مشاهده و اندازهگیری است. به متغیر تعدیل کننده گاهی متغیر مستقل فرعی نیز گویند. برای نمونه متغیر جنسیت در بررسی رابطه روش تدریس و یادگیری دانشآموزان یک متغیر تعدیل کننده است.
متغیر کنترل: اگر متغیر میانجی قابل سنجش و اندازه گیری باشد و پژوهشگر بخواهد اثرات آن را کنترل و در مدل حذف کند به آن متغیر کنترل گویند. چون در در یک پژوهش اثرات همه متغیرها قابل بررسی نیست، پژوهشگر اثرات برخی متغیرها را از طریق کنترل آماری یا کنترلهای تحقیقی خنثی میکند. اینگونه متغیرها که اثرات آنها توسط پژوهشگر قابل حذف است را متغیر کنترل گویند.
متغیر مداخلهگر : اگر متغیر میانجی قابل سنجش و قابل حذف نباشد به یک متغیر مداخله گر تبدیل می شود. متغیر مداخلهگر از دیدگاه نظری بر متغیر وابسته تاثیر دارد اما قابل مشاهده و سنجش نیست تا به عنوان متغیر تعدیل کننده محسوب شود و نه اثرات آن قابل خنثی کردن است تا به عنوان متغیر کنترل محسوب شود.
انواع متغیرها در ادبیات مدلسازی معادلات ساختاری
از منظر نحوه اندازه گیری متغیرها به دو دسته متغیرهای پنهان و آشکار تقسیم می شوند:
متغیر مشاهده شده یا آشکار: متغیرهایی هستند که مستقیما قابل مشاهده و اندازه گیری هستند. برای این متغیره اغلب وسیله ای برای اندازه گیری وجود دارد مانند قد، وزن،فشار خون و . . همچنین هر یک از سوالات پرسشنامه متغیر آشکار هستند.
متغیر پنهان یا مکنون: به طور مستقیم اندازه گیری نمی شود و با استفاده از دو یا تعداد بیشتری از متغیرهای مشاهده شده در نقش معرف سنجش می شود. مثلا متغیر میزان افسردگی به طور مستقیم قابل اندازه گیری نیست و از طریق تعدادی سوال این متغیر سنجش و اندازه گیری می شود. در واقع این گونه متغیرها برآیند نمرات چندین سوال می باشند. هوش، افسردگی، انگیزه، اعتماد و مفاهیمی از این قبیل جز متغیرهای پنهان هستند.
متغیر خطای اندازه گیری: نوعی متغیر پنهان است چرا که مستقیما اندازه گیری نشده است و نشان دهنده تمام متغیرهایی است که آن معرف، غیر از پنهان مورد نظر اندازه گیری می کند.
در ادبیات مدلسازی معادلات ساختاری از دو نوع متغیر بیرونی و درونی مکررا نام برده می شود که به صورت زیر تعریف می شوند:
متغیر بیرونی یا برونزا: عنصری از مدل ساختاری که هیچ پیکانی به سمت آن نشانه نرفته و تحت تاثیر سایر متغیرها نیست. در واقع آنها متغیرهای مستقل هستند.
متغیر درونی یا درونزا: عنصری از مدل ساختاری که حداقل یک پیکان به سمت آن نشانه رفته است و تحت تاثیر سایر متغیرهای بیرونی در مدل است. متغیری است که هم می تواند وابسته و هم مستقل باشد.
یکی از راههای کاهش هزینه در انجام تحلیلهای آماری این است که خود محقق نسبت به ورود اطلاعات به نرم افزار اقدام نماید. چنانچه پس از انجام تحقیق قصد دارید خودتان پرسشنامه های جمع آوری شده را به نرم افزار SPSS یا Excel وارد نمایید، می توانید فایل پرسشنامه تحقیق خود را برای ما ارسال نمایید تا ما فایل خام جهت ورود داده ها به نرم افزار و آموزش نحوه ورود داده ها را برای شما ارسال نماییم.
مطالب این پست در حال تکمیل است. آموزش تصویری نیز در آینده به این پست افزوده خواهد شد.
در این پست قصد داریم آموزش کامل نحوه ورود داده ها به نرم افزار SPSS را آموزش دهیم. به گونه ای که خودتان بتوانید با استفاده از مطالب این پست اطلاعات تحقیق خود را وارد نرم افزار کنید. یکی از راههای کاهش هزینه در خدمات تحلیل آماری، ورود اطلاعات توسط خود محقق است. اما اگر بنا به دلایلی قصد ندارید خودتان داده ها را وارد نرم افزار نمایید ما می توانیم خدمات ورود اطلاعات به نرم افزار SPSS را برای شما انجام دهیم.
پس از ورود به نرم افزار SPSS ، در ابتدا با صفحه های به صورت زیر مواجه می شوید:
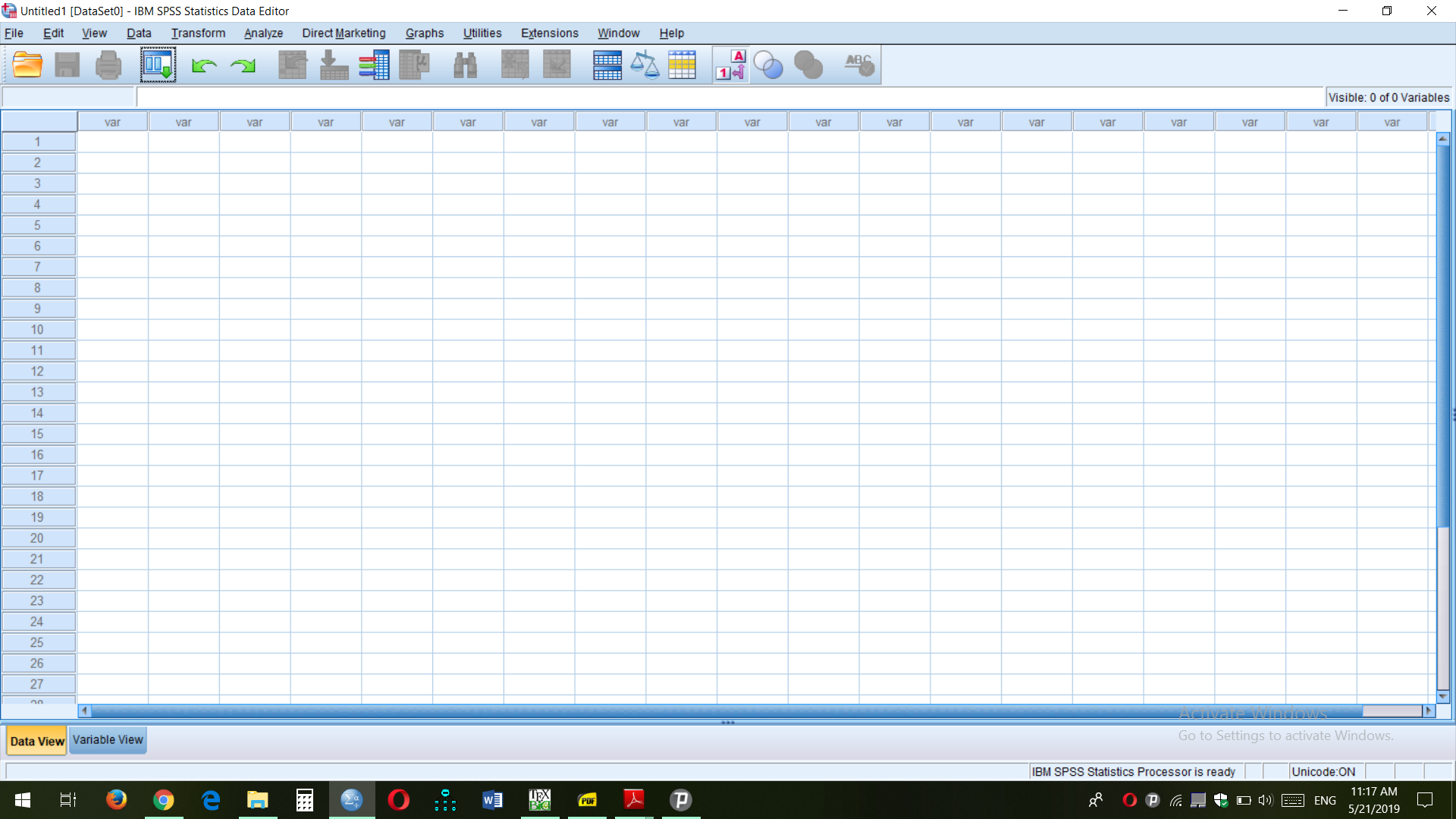
در قسمت پایین صفحه سمت چپ ود تب مشاهده می کنید: data view و variable view. برای ورود اطلاعات به نرم افزار SPSS لازم است ابتدا روی تب variable viewکلیک کرده و متغیرهای تحقیق خود را وارد نمایید. با کلیک روی این تب با صفحه ای به صورت زیر مواجه می شوید:

در این صفحه می توانید ویژگی های مختلف مربوط به هر متغیر را در هر ردیف وارد کنید. در ادامه به توضیح هر یک از این ویژگی ها می پردازیم:
Name: در این قسمت نام متغیر مورد نظر وارد می شود. نام متغیر بایستی دارای ویژگی های زیر باشد. البته در صورت عدم رعایت هر یک از موارد خود نرم افزار SPSS خطا می دهد. بنابراین نیازی به نگرانی از بابت نام متغیر نیست. فقط بهتر است نام متغیر تا حد ممکن کوتاه و تداعی کننده متغیر مورد نظر باشد.
1. باید یکتا باشد،یعنی نمیتوان دو متغیر با یک نام داشت.
2. باید حداکثر 64 کاراکتر داشته باشد.
3. نباید با کاراکترهای # $ . _ شروع شود.
4. کاراکترهای بعدی میتوانند ترکیبی از حروف بزرگ و کوچک ، اعداد و کاراکتر های @ ، # ، $ ، ÷ ، × ، و. باشد.
5. نمیتواند شامل فاصله باشد.
6. نباید با یک نقطه یا خط تمام شود.
7. کلمات کلیدی مانند ALL ، AND ، BY ، EQ ، GE ، LE ، LT ، NE ، NOT ، OR ، TO و WITH که spss از آنها به عنوان عبارتهای محاسباتی و منطقی استفاده میکند، نباید به تنهایی به عنوان اسم متغیر قرار گیرند.
Type:

توضیحات اضافه خواهد شد
Width:توضیحات اضافه خواهد شد
Decimals:توضیحات اضافه خواهد شد
Lables: گاهی اوقات ممکن است نیاز به ارائه توضیحاتی در مورد نام متغیر باشد. این توضیح می تواند به زبان فارسی نوشته شود و اغلب در خروجی های نرم افزار این برچسب به جای نام اصلی متغیر ظاهر می شود که باعث میشود درک خروجی راحت تر باشد.
Values: این قسمت برای کدگذاری مقادیر متغیرهای کیفی کاربرد دارد. به عنوان مثال فرض کنید متغیر جنسیت دارای دو مقدار مرد و زن می باشد. چنانچه قصد داشته باشیم به مرد کد 1 و به زن کد 2 را نسبت دهیم، از این بخش این کار را انجام می دهیم. با کلیک روی خانه مربوطه و کلیک روی نقطه چین
 ،پنجره ای به صورت زیر باز می شود:
،پنجره ای به صورت زیر باز می شود:

ابتدا در قسمت value عدد 1 را وارد کنید. سپس در قسمت Lable بنویسید "مرد". با اینکار گزینه Add فعال می شود که با کلیک بر روی آن عبارت (1=مرد) در باکس پایین ظاهر می شود. سپس در قسمت value بنویسید 2 و در قسمت label کلمه "زن" را وارد و روی Add کلیک کنید. با اینکار عبارت (زن=2) در باکس پایین ظاهر می شود.
اگر متوجه شدید که در کدگذاری اشتباه کرده اید می توانید از گزینه های change و remove استفاده نمایید. با کلیک روی عبارت مورد نظر در باکس پایین گزینه remove فعال می شود و کد اختصاصی و برچسب مربوطه مجددا در قسمت های value و label ظاهر می شوند. . با کلیک روی دکمه remove کدگذاری مربوطه حذف می شود. ولی اگر تغییراتی در کد یا برچسب اعمال کنید، گزینه change فعال می شود که با کلیک بر روی آن تغییرات مورد نظر اعمال می شوند. در نهایت بر روی ok کلیک کنید تا کدگذاری مد نظر شما به نرم افزار معرفی شود.
Missing: در این قسمت تنظیمات مربوط به شناساندن مشاهدات مفقود (یا گمشده یا بی پاسخ) به SPSS وجود دارد. با کلیک روی خانه مربوطه و کلیک روی نقطه چین
 ،پنجره ای به صورت زیر باز می شود:
،پنجره ای به صورت زیر باز می شود:

گزینه پیش فرض نرم افزار گزینه No missing values است. پیشنهاد ما استفاده از این گزینه است. با استفاده از این گزینه هنگام ورود داده ها نیاز به کار خاصی نیست و تنها کافیست خانه مورد نظر را خالی رها کنید. SPSS خانه های خالی را به عنوان missing شناسایی میکند.
اما ممکن است بنا به دلایل خاصی (مثلا تمایز قایل شدن بین بی پاسخ ها و پاسخ های مخدوش) بخواهید خودتان مقادیری را به نرم افزار به عنوان مشاهدات گمشده معرفی کنید. با انتخاب گزینه Discrete missing values می توانید تا سه مقدار به عنوان مشاهدات missing به نرم افزار معرفی کنید. توجه کنید که مقادیر اختصاص داده شده بایستی با مقادیر موجود در مشاهدات متفاوت باشند. به عنوان مثال اگر متغیر شما سن افراد باشد اختصاص عدد 30 برای مشخص کردن مشاهده گمشده منطقی نیست و مثلا می توانید از اعداد 1- یا 999 استفاده کنید. گزینه سوم با عنوان range plus one optional discrete missing value امکان این را فراهم می کند که دامنه خاصی از مقادیر را به عنوان مشاهده گمشده تعریف کنید. مثلا اگر بخواهید اعداد بین 10 تا 20 به عنوان مشاهده گمشده معرفی شوند، در قسمت low عدد 10 و در قسمت high عدد 20 را وارد کنید. همپنین می توانید یک مقدار اختیاری را نیز به عنوان missing تعریف کنید. مثلا اگر قصد داشته باشید عدد 99 را برای اینکار اختصاص دهید، در باکس آخر عدد 99 را وارد کنید. در پایان روی دکمه ok کلیک کنید.
Columns:توضیحات اضافه خواهد شد
Align:توضیحات اضافه خواهد شد
Measure: در این قسمت مقیاس اندازه گیری متغیرها وارد میشود. برای اطلاعات بیشتر در مورد انواع مقیاسهای اندازه گیری
کلیک کنید. با کلیک روی خانه مربوط به این ویژگی، 3 گزینه برای انتخاب ظاهر می شود:

چنانچه داده های ما با مقیاس نسبی یا مقیاسی اندازه گیری شده باشند، گزینه Scale ، چنانچه با مقیاس ترتیبی اندازه گیری شده باشند گزینه Ordinal T، و چنانچه با مقیاس اسمی اندازه گیری شده باشند گزینه Nominal را انتخاب می کنیم.
Role:توضیحات اضافه خواهد شد
درباره این سایت